

How we doubled Zod performance to speed up Typescript validation
In Zod we trust.

At Numeric, we rely heavily on Zod for runtime type validation in our TypeScript stack. While Zod has served us well, we ran into some hefty performance issues when processing large datasets. To address this, we forked Zod, applied targeted optimizations, and achieved a 2x improvement in validation speed. Here’s what we did.
Why Runtime Type Checking Matters in TypeScript
TypeScript’s static type system is effective, but runtime validation remains necessary when dealing with external data sources. Without runtime checks, compile-time types for external data are meaningless. They create a false sense of security that lets subtle data inconsistencies spread through your system.
What is Zod?
Zod is a TypeScript-first validation library that ensures runtime data matches expected types. Developers define schemas that describe the expected structure and constraints of data, and Zod then validates inputs against those schemas. It also eliminates redundant type declarations by inferring static TypeScript types directly from the schemas.
Beyond type checking, Zod offers features such as:
Transforms: Modify data while validating it
Pipes: Chain multiple validation steps
Coercion: Convert values (e.g., strings to numbers) during validation
While these features enhance developer experience, they introduce performance overhead and require a validation approach that can impact scalability.
Our primary use cases for Zod include:
Validating database query responses
Enforcing API contracts between frontend and backend
Verifying data from third-party integrations
Given these use cases, our goal was to enforce strict type checking with minimal processing overhead. We sought surgical optimizations to improve performance while maintaining Zod’s API for an easy migration path.
The Bottleneck: Overhead from Deep Copying
By default, Zod validates data immutably—it returns a new object instead of mutating inputs. While this aligns with functional programming principles, it introduces significant overhead when processing large datasets.
Symptoms
In one real-world scenario, parsing 500,000 account objects took around 2 seconds using standard Zod validation. The performance overhead caused noticeable event loop delays and, in some cases, server OOM crashes due to excessive memory allocations (as well as overly nested promises when using async function variants).

A visualization of Zod parsing taking the majority of the CPU time it takes to run queries against our databases.
For the sake of reproducibility, here’s a simplified version of one of the schemas we benchmarked. We’ll use this naive benchmark of the time to parse an array of 500,000 account objects as a proxy for general library performance and improvements; it’s simple and easy to reproduce with some fake data. However, during experimentation and implementation, we augmented this with other benchmarks based on our production usage, as well as more default profiling.

The situation became dire enough that we introduced a configuration flag to disable type checking for certain high-throughput workloads—a clear signal that something needed fixing.
The Optimization: Bye-Bye, Deep Copies
We modified Zod’s validation logic to return the original object when validation succeeds, instead of creating a deep copy. This drastically cut down CPU and memory usage.
To enable this optimization, we had to remove features that rely on returning a new object, including:
catchcoercedefaultintersection/and(in favor ofmerge)pipepreprocesstransform
For many users of the library, these are core features, which is why Zod itself can’t support something like this with minimal changes. But for us, our system already separates transformation logic from validation, so removing these features was a reasonable trade-off.
Zod’s internal functionality must be understood to understand why this optimization can be implemented in an elegant and contained manner. At its core, Zod’s validation logic is really just casting any to stronger types, with a bunch of checking along the way. The logic is illustrated in this simplified example:

As long as the validation function ensures type correctness of the input object, there’s no strict need to return a cloned object. Eliminating deep copying doesn’t change how TypeScript will enforce the types of the returned value downstream.
(Clever readers may interject here that a proper in-place validation function should probably be using the asserts operator. While relying on type narrowing via asserts would be great, the implementation would require much deeper changes in Zod’s plumbing. We’re hoping to see something like this strategy come out in Zod 4, perhaps!)
Implementation Details: Optimizing _parse
Our optimization focused on ZodObject#_parse, the function responsible for validating and processing objects against schemas.
Key Changes:
The macro-optimization here is validating data in place and then returning the input object itself if validation passes. This gives us around a 1.5x speed boost. Getting it up to the titular 2x required a few more micro-optimizations such as:
Use direct key lookups instead of iterating through properties, reducing CPU cycles.
Handle excess properties efficiently, stripping or reporting unknown keys without redundant processing.
With these changes, we saw a 2x validation speed improvement across our benchmarks. Check out the forked source code on Github.
Trade-offs
This approach allows us a fairly surgical implementation (besides the removal of some features en masse). However, this comes with a good number of trade-offs that may only make sense for our specific use cases. Otherwise, we would have just PR’d to the main repository 🙂.
Directly modifying input data in
stripmode: extra keys are removed in place rather than on a cloned object. This is probably the biggest footgun introduced here. Optimally, we’d default topassthroughmode rather thanstripto match Typescript’s default behavior (without excess property checking), but changing such a default would be a much more in-depth and dangerous change.The input data itself is not type-checked: the returned value must be reassigned to enforce strict typing. Ideally, TypeScript’s
assertsoperator would be used, but that, too, would require more intrusive changes. This trade-off is not too bad, given it matches Zod’s own API. As an aside, a piece of essential reading for this subject matter is Alexis King’s article “Parse, don’t validate”.ZodIntersectionbehavior changes: previously,intersectionvalidated both schemas and merged results. With deep copying removed leading to the abovestripbehavior,intersectioncan lead to unexpected key deletions. Rather than get too clever here, we instead fully removedintersectionwith the recommendation to useZodObject#merge. For our use cases of only ever intersecting object types, the minutiae lost in the differences betweenmergeandintersectionare insignificant.
A massive kudos goes to Zod’s comprehensive test suite; with it, we caught and addressed these edge cases early in our implementation.
Rolling Out to Production
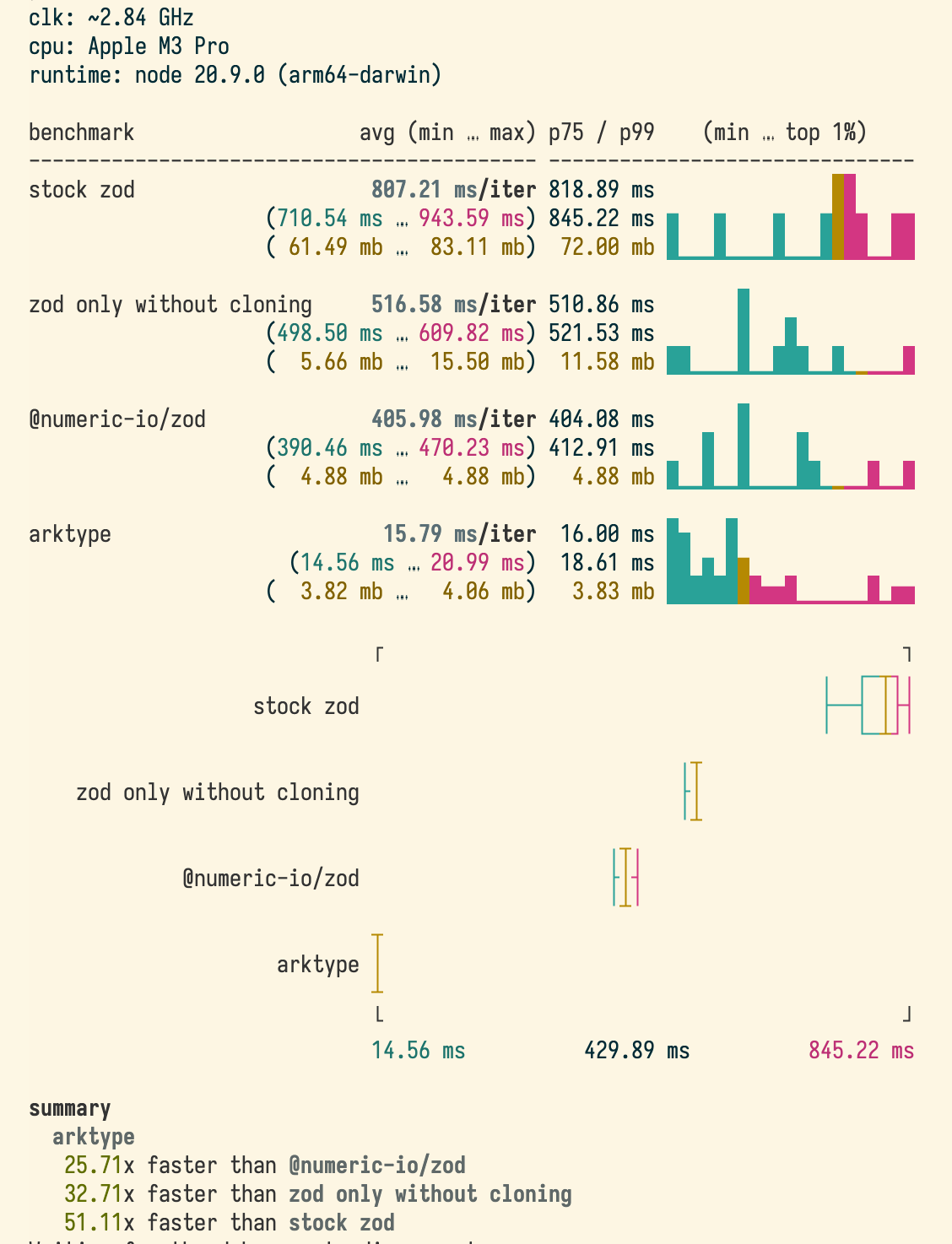
We tested our fork extensively using internal benchmarks on production servers. The results confirmed a 2x validation speed improvement on large datasets.
Migration was straightforward—since our fork is a strict subset of Zod’s API, the primary change involved replacing our few remaining .transform() calls with a separate transformation step. Other validations continued to work as expected, with dramatically improved performance.
Looking Forward: Exploring ArkType
While Zod has served us well, we’re extremely excited about ArkType, a newer validation library leveraging JIT compilation. Based on the type definition, ArkType creates a function using the new Function(...) syntax that avoids a lot of the overhead from the deep recursive call stack that belabors libraries like Zod. ArkType consistently outperforms Zod—even our optimized fork—by a wide margin. The base Zod library benchmarked at around 40x slower than ArkType on the same set of 500K accounts, and our optimizations brought it down to 20x. ArkType remains the clear winner on speed and memory usage.
Given these numbers, why haven’t we switched yet?
Stability: Zod is battle-tested and well-supported. ArkType, while promising, is still maturing.
Developer Experience: We love the Zod API and have found ArkType’s ergonomics lacking in some areas.
Clear Use Cases: We adopt new tools when the need is clear and the benefits outweigh the migration effort. ArkType shows promise, but we need further validation before committing.
For now, our optimized Zod fork meets our production needs, but we’re actively testing ArkType for R&D projects.
Final Thoughts
In the JavaScript ecosystem, it’s almost too normalized to use a package for everything. This experience reinforced an important engineering principle: general-purpose tools don’t always scale perfectly for specific workloads.
Zod is an excellent validation library, especially for form inputs or simple API contracts, but its default immutability strategy can be a performance bottleneck in high-throughput applications. When we found ourselves working around these constraints, we took a deeper look and modified the tool to fit our needs. By eliminating redundant object allocations, we doubled validation speed while preserving most of Zod’s stability.
Our Engineering Philosophy
We believe in the ability to peer into abstractions and modify them when necessary. Libraries should serve our needs—not the other way around. By understanding and optimizing Zod, we unlocked significant gains without sacrificing maintainability.
If you’re running into similar performance issues, take a step back. Rather than blindly accepting defaults, challenge abstractions and consider whether they serve your requirements.
 | A guest post by
|
Hey, ArkType author here! Really cool to see you your interest in these kind of optimizations. There is so much potential!
Totally understanding wanting to not commit too early to a project that has just released its first stable version.
That said, if you're experiencing a DX gap, it likely boils down to familiarity rather than the API itself. In a recent post, I highlighted a way to use the API that doesn't involve strings at all and is still much shorter and more expressive than Zod:
https://x.com/arktypeio/status/1898719166733136265
If you do use the primary syntax, once the parallel with TypeScript clicks and you can combine it with `.narrow` and `.pipe` to customize and transform, it's extremely expressive! The functionality is a superset of Zod's and definitions are ~50% shorter on average.
Would love to answer any questions you have on the ArkType Discord! 🚀
https://arktype.io/discord
Hey, ReScript Schema author is here. i think you might find it to be the best solution for your problem.
https://dev.to/dzakh/javascript-schema-library-from-the-future-5420